

Table of Contents
Image recognition is a cutting edge technology that is actively used by businesses.
Education, insurance, healthcare, manufacturing, agriculture, and even security companies already rely on image recognition systems and benefit from using them on a daily basis. Just check out our blog post dedicated to the most interesting use cases of image recognition, and you will be quite impressed and surprised.
Here at Altamira we have software development experts who already worked on image recognition apps and created proof of concept for insurance business. And today one of those specialists would like to share his expertise and knowledge with you.
Max Galaktionov is a valuable member of our tech team with more than 15 years of development experience. He will talk about image recognition in a nutshell and explain some practical aspects of training such smart systems. Max will also tell us how image recognition can be used for car damage detection. So, without further ado, let’s proceed to this very interesting topic right away.
Crucial basics of Computer Vision
To understand the essence of image recognition, it is necessary to start with the definition of computer vision and its principles of work. Basically computer vision is a scientific and engineering task of allowing computers to get a high-level understanding of image or video content.
The common tasks within computer vision include many processes such as preparing, processing, analyzing and gathering complex data in the form of numerical predictions of what is depicted on a visual content. For example, computer vision is already actively used in the manufacturing industry to detect defects in equipment, perform visual search, and preserve high packaging standards.
Computer Vision goals include but are not limited to object detection, image recognition, image classification, learning, and further event detection. In this particular article we’d like to focus more on image recognition model, its specifics and use cases. We will also provide some tips on how to train image recognition.
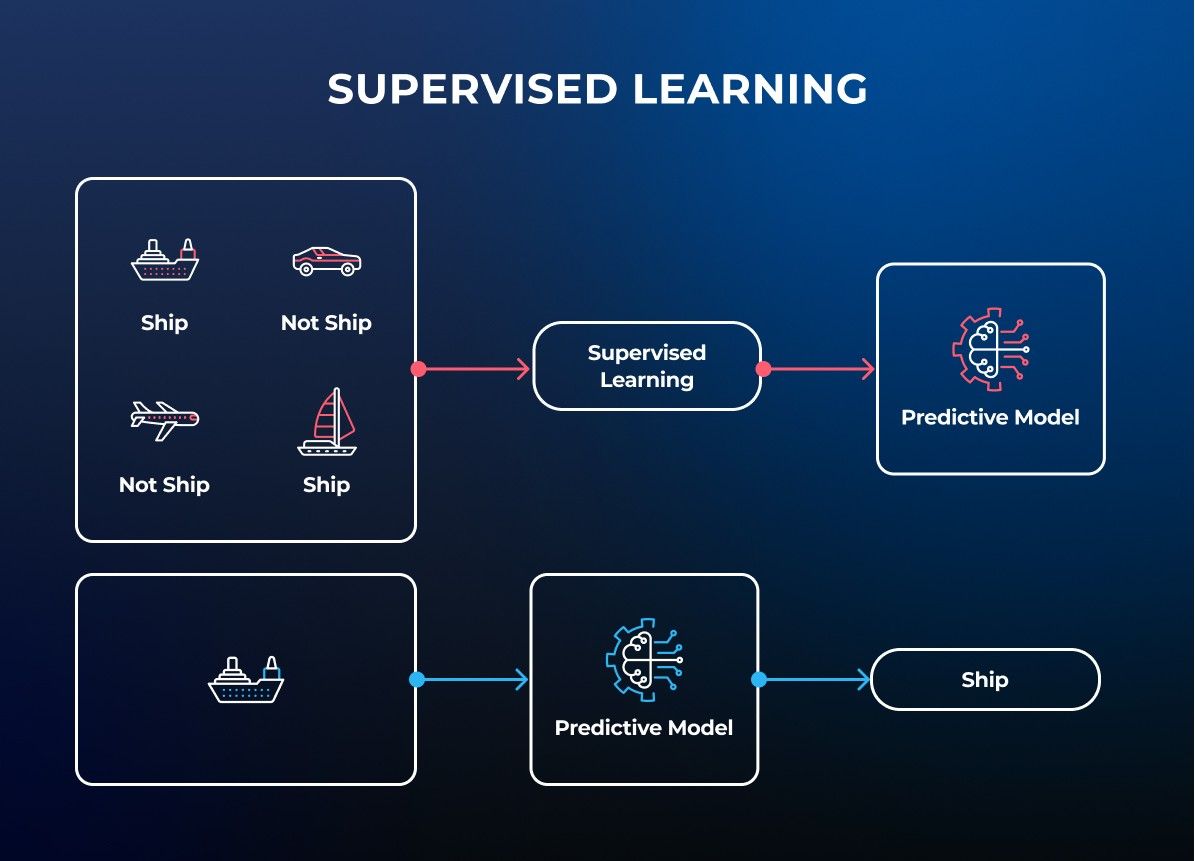
How Image Recognition works
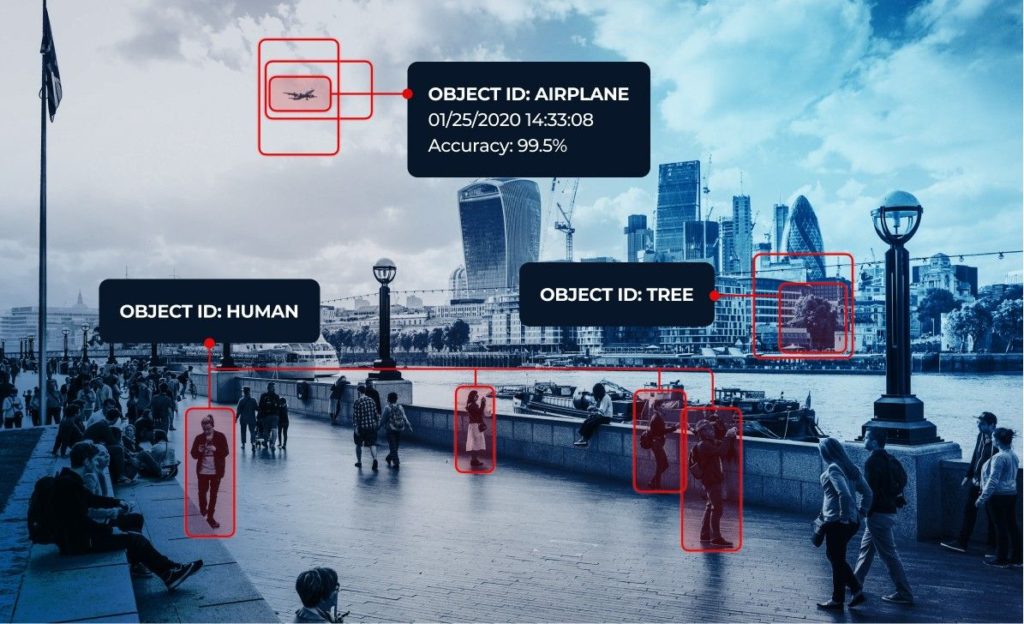
The basic principle that lays beneath the vast majority of image recognition solutions is deep convolutional neural networks (CNNs). Convolutional neural network is a multilayered neural network built to detect complex features, similarities and patterns inside the data.
The first layer of the image recognition models is encoder. Encoder is responsible for statistical pattern analysis on pixels of images that correspond to the classes (or labels) they’re attempting to predict.
The data from the encoder then goes to connected or dense layers that output confidence scores for each label. Image recognition models output confidence scores for each class and image. Label is assigned for image and object with the highest level of confidence and if the confidence score is higher than particular threshold. In case of multi-class recognition several labels can be assigned with certain precision.
With the high probable precision of the 95%, convolutional neural network is very sensitive to datasets that have to be huge and require lots of resources to be trained.
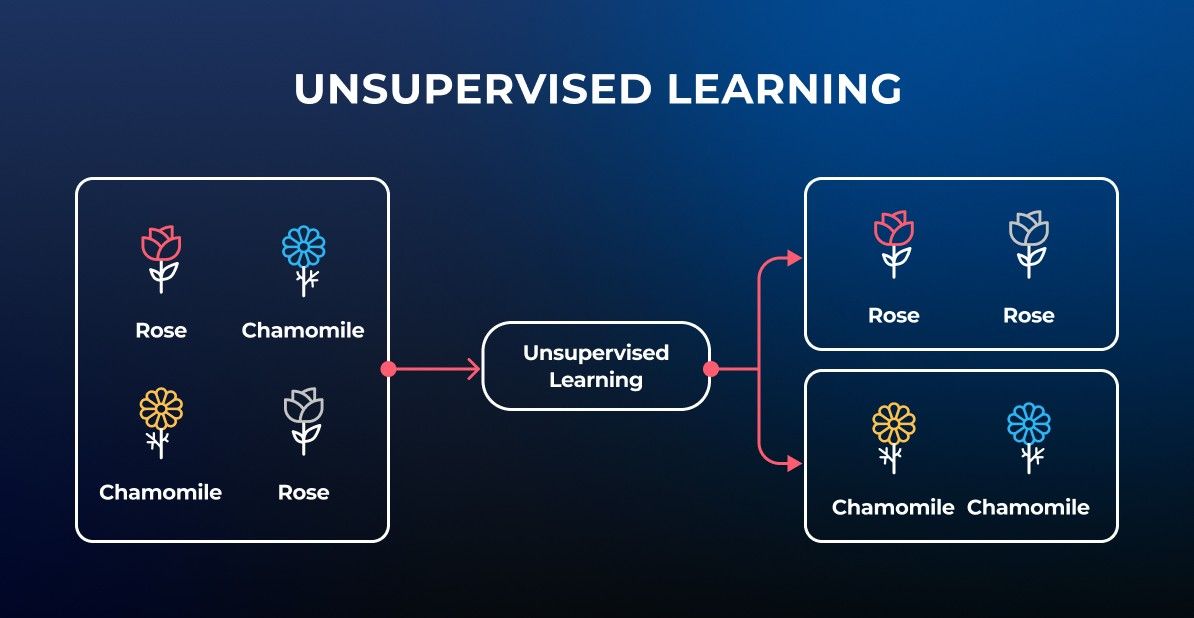
Image classification task
As we’ve mentioned earlier, image recognition is a computer vision task that tends to identify targeted objects on image or video, and then perform image classification, object detection and its labeling to a certain category. The list of object categories has to be classified into so-called targeted classes.
In addition to labeling objects, a confidence score represented in numeric or percentage format is considered a one more crucial metric. And now let’s delve into some practical aspects and find out how image recognition algorithms are trained.
Practical aspects of image recognition
To build great image recognition software for business is not enough, since such a solution will require proper training. After all, to benefit from an image recognition application, you need it to be able to analyze an entire image, identify to what category an image belongs, and then perform right image classification, pattern recognition or object detection. And that’s exactly what proper model training helps to achieve. Let’s talk about it right now and see how it works.
Dataset organization
Everything starts with preparing a quality dataset for training. Such a dataset has to contain pre-labeled data of images. To increase precision of the algorithm the dataset should be as huge as possible and contain up to millions, or even billions units, for each class that needs to be classified.
Also, a separate dataset should be prepared for further testing and tuning procedure. Such datasets are usually smaller and contain from 10% to 33% capacity of the main dataset.
Image recognition model training
As it will be too complex for convolutional neural networks to understand the whole image as a matrix of pixels and analyze it, each image should pass through the set of filters.
Then the image data will be transferred to convolutional neural networks in the form of feature maps. The layers of the model can analyze features of the feature maps with high precision and deep hierarchy building.
All feature maps (or sections) are normalized, usually using Rectified Linear Units or ReLu, to increase the speed and effectiveness of final model learning.
Model tuning (or fine-tuning)
Fine-tuning is a process of analysis and choosing perfectly fitting parameters of model training. In general that means that we rebuild our model (in a form of layered network) by learning it. The layering happens at a slow rate by randomly reordering layers within the model with further increasing efficiency of the model. This is achieved by building better internal mapping of layers.
Model tuning is an important process that greatly increases the accuracy of the trained model. It is highly recommended to do tuning on each iteration of model training, though it’s important to remember this is an expensive process by resources and time.
Model accuracy without tuning
Model accuracy with tuning
Model testing
Testing of the image recognition model is performed on the validation data set that is used on separate iterations of training and randomized afterwards. It can be provided automatically and the result has to be compared to threshold or desired accuracy.
In case the result is unsatisfactory, the model can be retrained with another set of fewer parameters. There probably will be more iterations and lower learning rate to increase model interaction with data. Also the cross-validation can be used. It implies splitting the main and validation dataset for the smaller chunks and using them repeatedly. In case of cross-validation, the test dataset must be held separately.
Quality Improvement
Once the model is properly trained, you can proceed with its quality improvement. To improve the quality of a certain image recognition model, it is recommended to follow these three key steps.
#1 Increase the size of dataset
Convolutional neural networks are sensitive to training data set sizes. So to significantly increase the prediction accuracy, your image dataset has to reach a huge size of millions of images per classification label.
#2 Perform data augmentation
This is an approach that allows to increase image recognition accuracy with datasets not big enough, and to achieve the desired numbers. Data augmentation implies insignificant changes of samples.
For example, you can modify samples by random transformations – mirror image, change angle, make it grayscale etc. These transformations allow to increase dataset size in a very simple and yet effective way, and to improve the training process.
#3 Do cross validation (k-Fold)
This is a highly effective method that involves repeatedly splitting dataset to training set and validating the sets with a coefficient (k). The model is being learned with a training set and tested with a validation set. And then the model is saved. Once it is done, another validation set is selected and model retrained again, unless all iterations are finished.
The final score will include an average of all iterations. Although cross validation is a great method, we do not recommend using it for tasks with huge amounts of classes. The thing is that in this particular case the model will not be able to learn effectively.
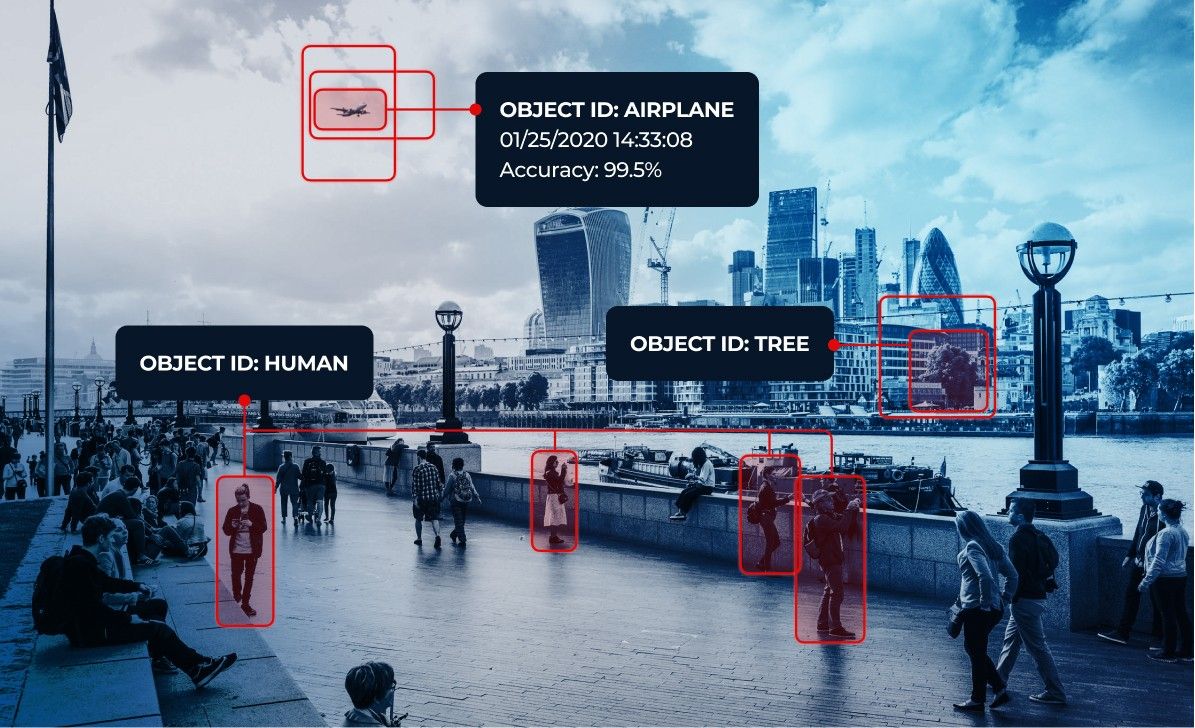
How image recognition is used by businesses
Thanks to its similarity to how the human brain and vision work, image recognition became a must-have for many businesses. It allowed to automate a lot of processes where human labor was always used.
Speaking about business industries that benefited the most from computer vision tasks and image recognition solutions there are:
Car damage recognition software
The Altamira team has already implemented image recognition to help insurance businesses with detection of car damage. Thanks to a deep neural network, our proof of concept and future smart solution can easily detect what kind of damage is present on a car, and then help insurance agents to decide what kind of compensation should be issued for every car crash case. And now let’s take a sneak peek into how everything works.
Our solution for car damage recognition is a set of algorithms and trained AI models that can analyze an image or set of images and understand if the car was damaged, how severely and in what particular place. This is achieved by a set of gates specializing on certain tasks, increasing overall precision and effectiveness of the whole solution.
Every gate works on top of a special model trained on a dataset that contains a number of classes to label images of the car by the most narrow parameters to be analyzed. For example, the second dataset was trained by 5 levels of damaged cars to achieve best precision of damage level detection.
After passing all gates, the most accurate score of predictions is output to a person who uploaded the image. This allows that person to understand if the car was damaged and proceed with the insurance case.

FAQ
What tasks can be performed by image recognition?
There are many of them, but the most popular tasks that businesses benefit from would be: facial recognition that is used for security purposes, image classification and segmentation empowering robotics and self-driving vehicles, scene and object characters identification, and object recognition used mainly for visual search.
What technologies are used for image recognition systems?
Many of such solutions are built using Python programming language, and such advanced technologies as artificial intelligence and machine learning. For deep learning models programmers use deep-learning APIs like Keras or else. As to AI and machine learning, they help software engineers to train the system, increase its accuracy, and ensure better performance.
What businesses already use image recognition?
Speaking about business giants, we would name LinkedIn, Pinterest, Google, Sephora, Salesforce, and many more. Each year more and more companies invest in image recognition solutions. And according to statistics, the market of such apps is expected to increase by 20,7% during the upcoming 5 years. So now is the time to think about implementing image recognition for your business.
To conclude
It is hard to underestimate the importance and power of image recognition. By introducing it and building image recognition apps for business, you can cut costs, unload your employees, reduce possibilities of human errors, and even increase accuracy and efficiency of your work.
For many industries such as insurance, image recognition became an irreplaceable helper. If you invest in your own car damage recognition system and keep training and improving it, you can turn your company to a whole new level. Different kinds of the car damages will be detected within seconds, and all the insurance cases will be solved way faster as well.
Altamira has experienced developers and quality assurance specialists who can help you with image recognition app development. Whatever idea you have in mind, we can turn it into a proof of concept and then transform it into a real project that will improve and amplify your business.



